Unit 4: Your First SDMX Structural Model

In this unit, the Logical Data Model to SDMX Information Model mapping we created in the previous unit will be expanded to include additional elements so as to complete the SDMX Information Model definition.
Your first SDMX Structural Model
Now that the statistical structural model has been mapped to SDMX terminology, the essential elements are in place. The work so far however has primarily focussed on defining the characteristics of statistical observations present in a table.
These concepts now need to be represented according to SDMX maintainable structure types in a manner consistent with using them as a part of a statistical system. To achieve this objective, we need to introduce a number of additional SDMX structures.
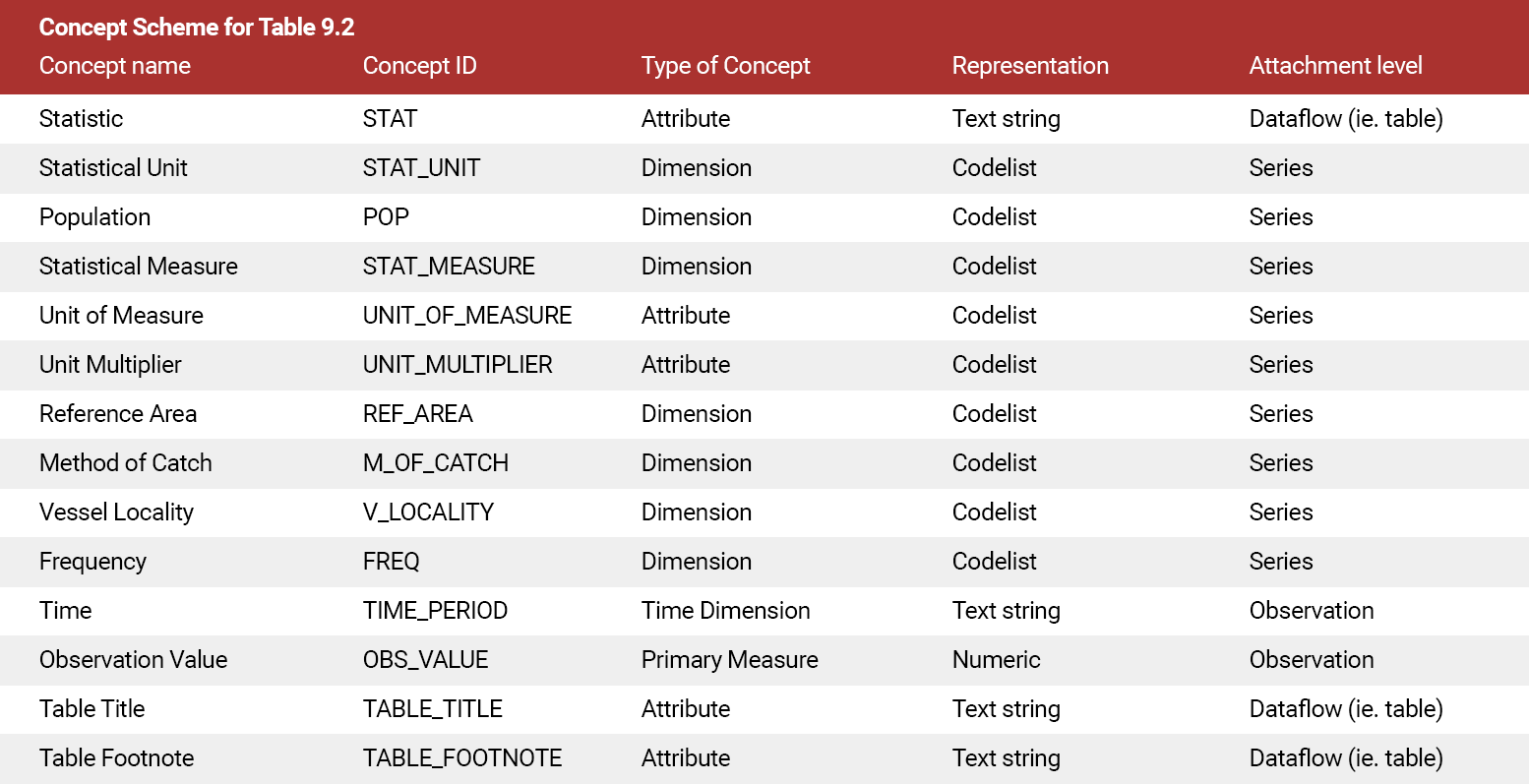
SDMX concept scheme
A concept scheme is a container for SDMX concepts.
Recall that the SDMX concepts are dimensions, attributes, and measures. The primary measure is often referred to as the “observation value”.
A statistical system may have one or many concept schemes depending upon factors such as the approach to data governance or the degree of centralization/decentralization of the statistical system.
For data governance purposes, the concept scheme is versionable.
SDMX concepts and artefacts generally are identified by an ID, in this case, a concept ID. The concept ID is the unilingual, unique identifier of the concept and is the primary element referenced by data production tools. All of the other items used to describe, in this case, concepts, such as concept name and concept description support internationalisation. For a single unique concept ID, the name and description may be translated into as many languages as is relevant for the statistical system. It should be noted however that when an additional language is added, ALL concepts and artefacts should be translated to this language and mechanisms put in place to ensure that these translations are maintained over time.
The Concept Scheme for our Fish Catch By Vessel Locality is shown in the following table.
Select the table to enlarge. ![]()
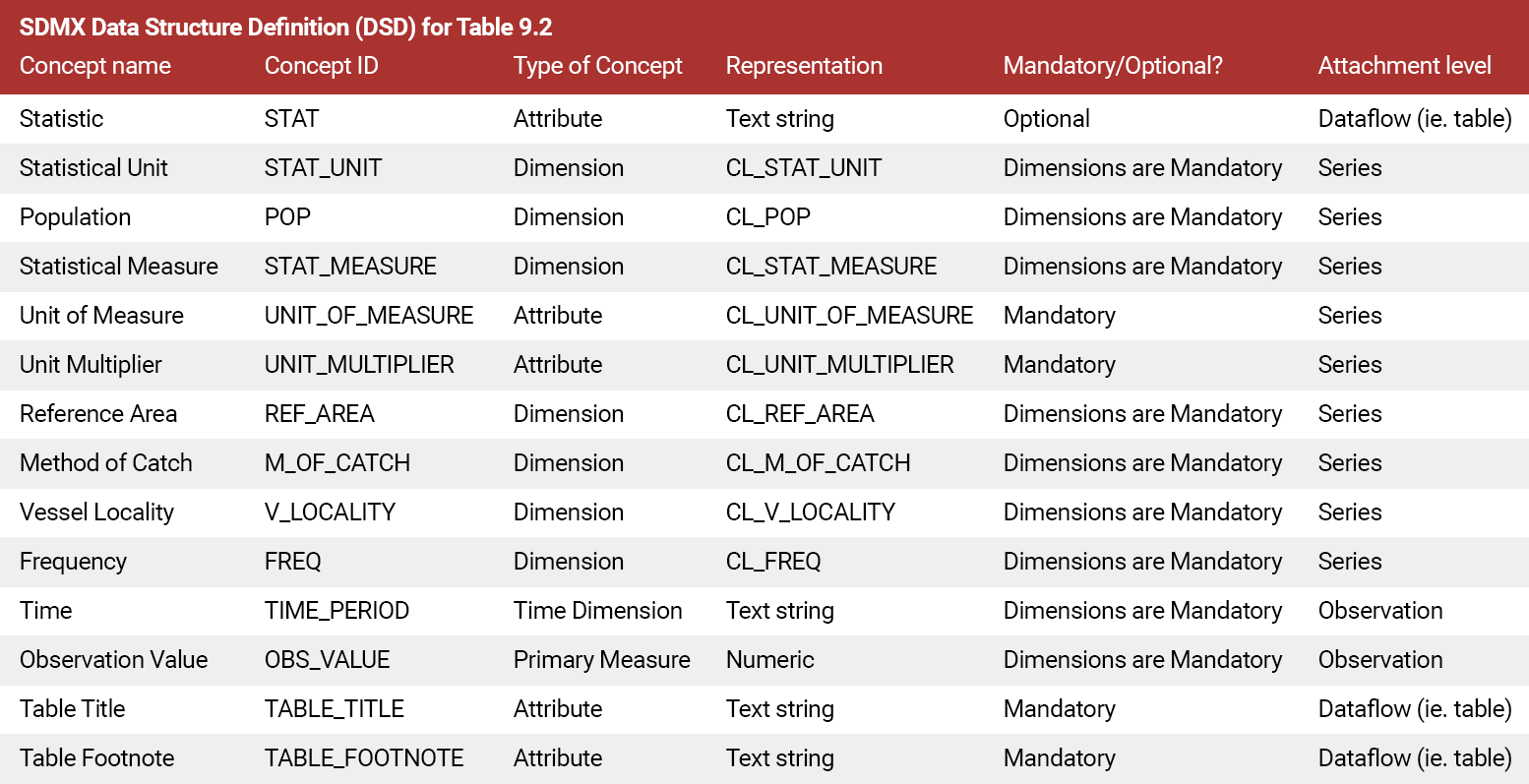
SDMX Data Structure Definition (DSD)
In SDMX, a dataset structure is formally defined by using a Data Structure Definition (DSD).
A DSD is a container consisting of dimensions, attributes, and measures concepts along with their associated representations.
Dimensions in a DSD are used to unambiguously locate an observation in a dataset.
For data governance purposes, the DSD is versionable.
In a statistical system:
- There will be many datasets, many DSDs.
- Datasets will be received from data providers, changed by internal processes, published in online portals, and reported to other organisations.
- There will be many dimensions, attributes, and measures.
- Some dimensions, attributes, and measures will be reused in multiple datasets.
- There will be many codelists.
- Some codelists will be reused in multiple dimensions and coded attributes. For example, sex, age, reference area, frequency, unit of measure.
- Managing these structural metadata, maximizing coherence and consistency, both within an individual organisation as well as throughout the entire data lifecycle, including with external data partners, is an important aspect of assuring quality in the statistical system. Employing data governance processes is an important aspect of this work. Managing and sharing the structural metadata in a robust tool, such as the Fusion Metadata Registry (FMR), is another important aspect of this work.
- There are numerous SDMX cross-domain codelists that are recommended for use to assist with these efforts.
The SDMX DSD for our Fish Catch By Vessel Locality is shown in the following table.
Select the table to enlarge. ![]()
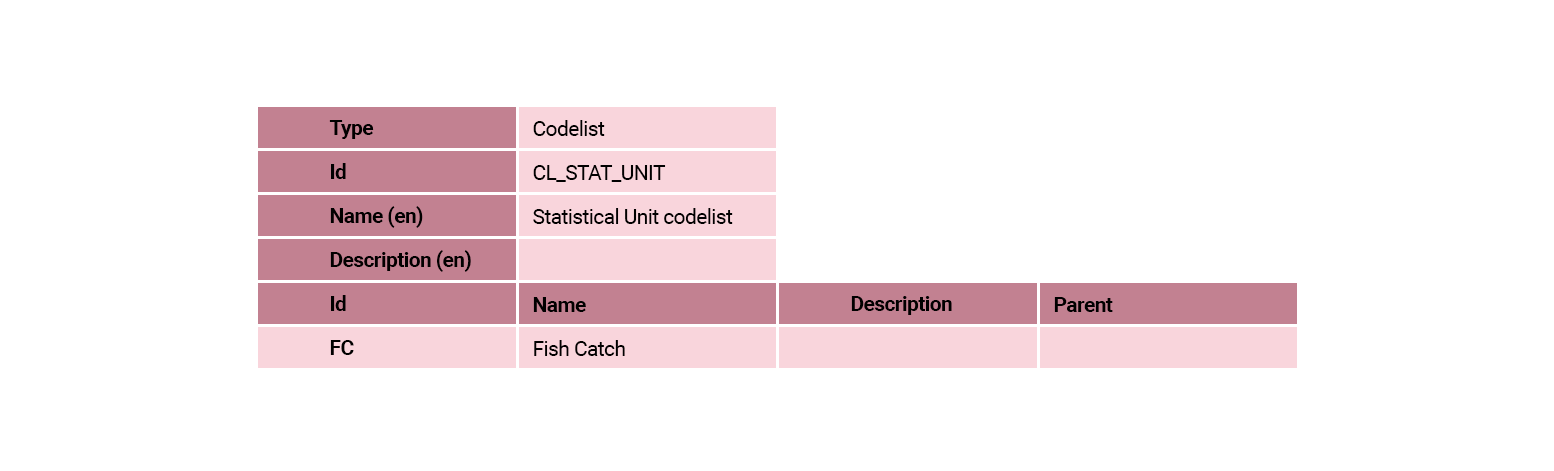
SDMX codelists
A codelist is a container for codes (classifications).
Codes associate an identifier (Id) with a name and optional description.
A codelist may be associated with (the representation of) multiple dimensions or attributes.
For data governance purposes, a codelist is versionable.
For each row in the concept scheme with “Representation = Codelist”, it is necessary to identify a codelist with the list of possible values. This may require the creation of a new codelist or alternatively, there may be a pre-existing codelist which could be reused. The pre-existing codelist may exist within the statistical system or there may a global codelist which could be used, such as a cross-domain codelist or codelist from a global DSD.
The new codelists are shown in the following tables.
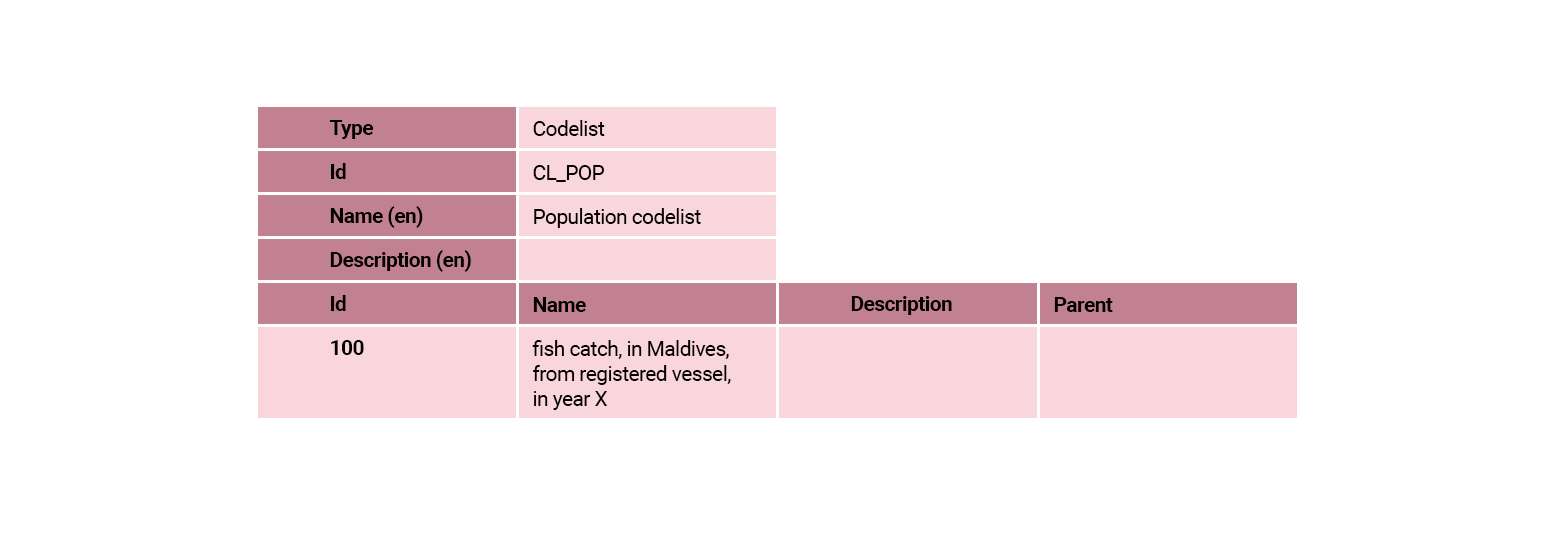
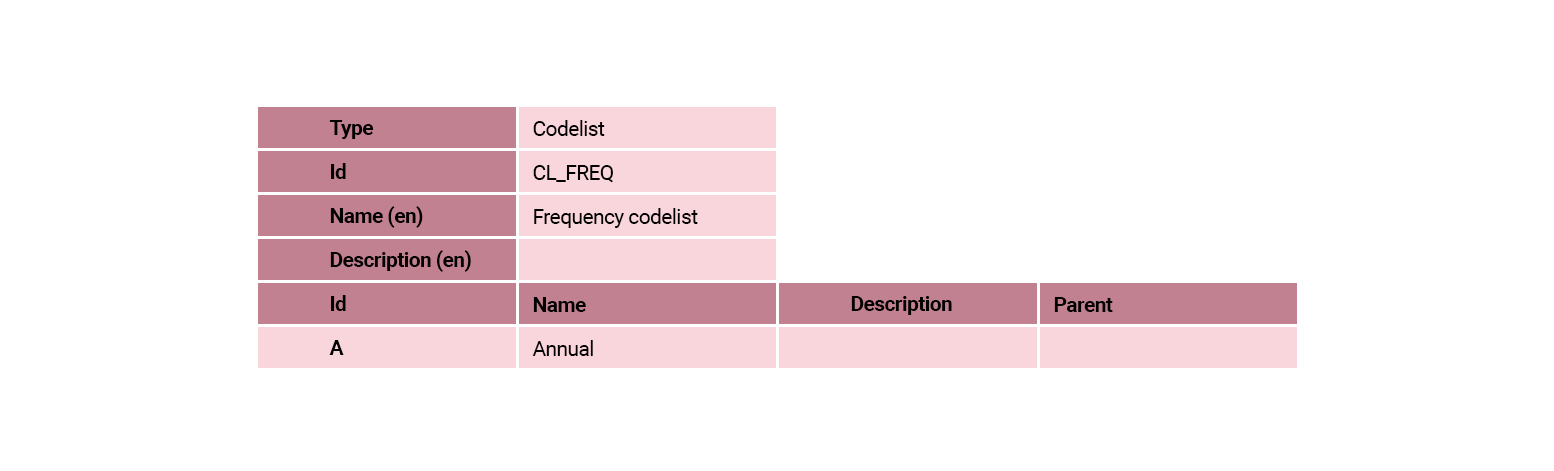
The codelists for our Fish Catch By Vessel Locality are shown in the following tables.
Select each codelist to enlarge. ![]()
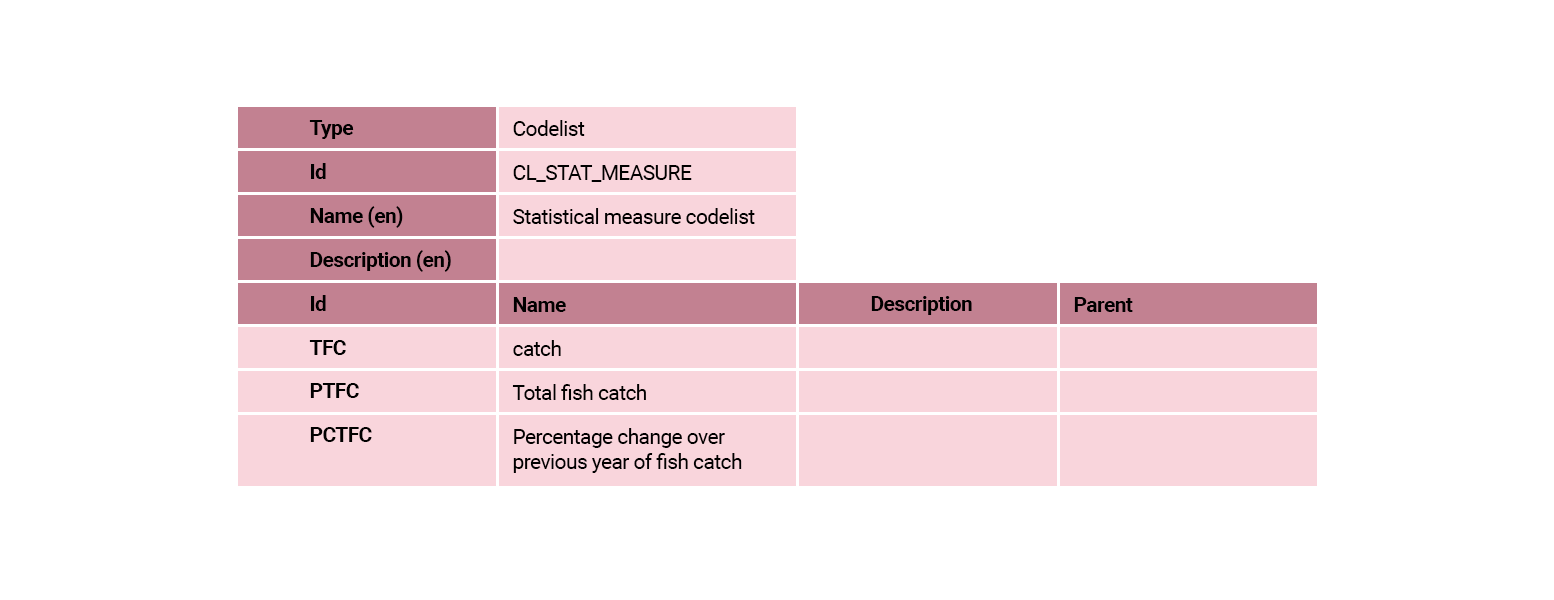
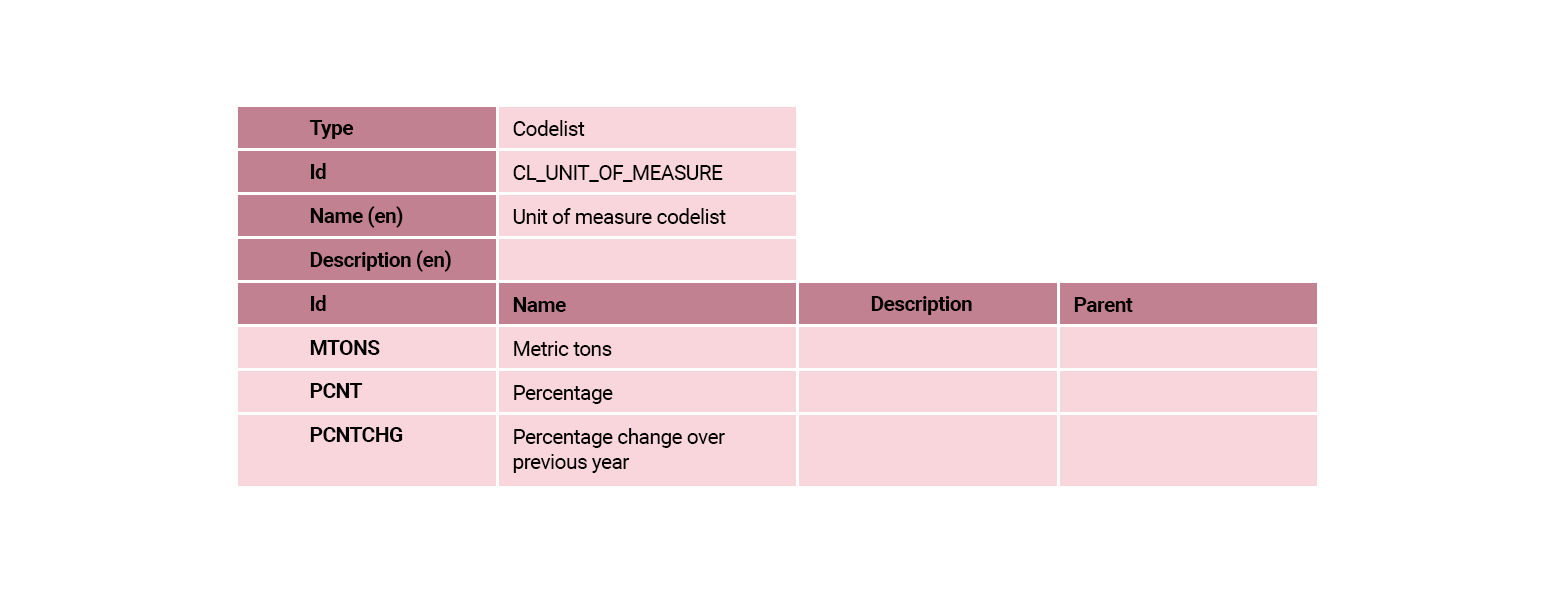
The CL_UNIT_MULTIPLIER codelist is one of the cross-domain codelists that are maintained by the SDMX governance groups. There are references to the Cross-Domain codelists in the support materials provided at the end of this module.


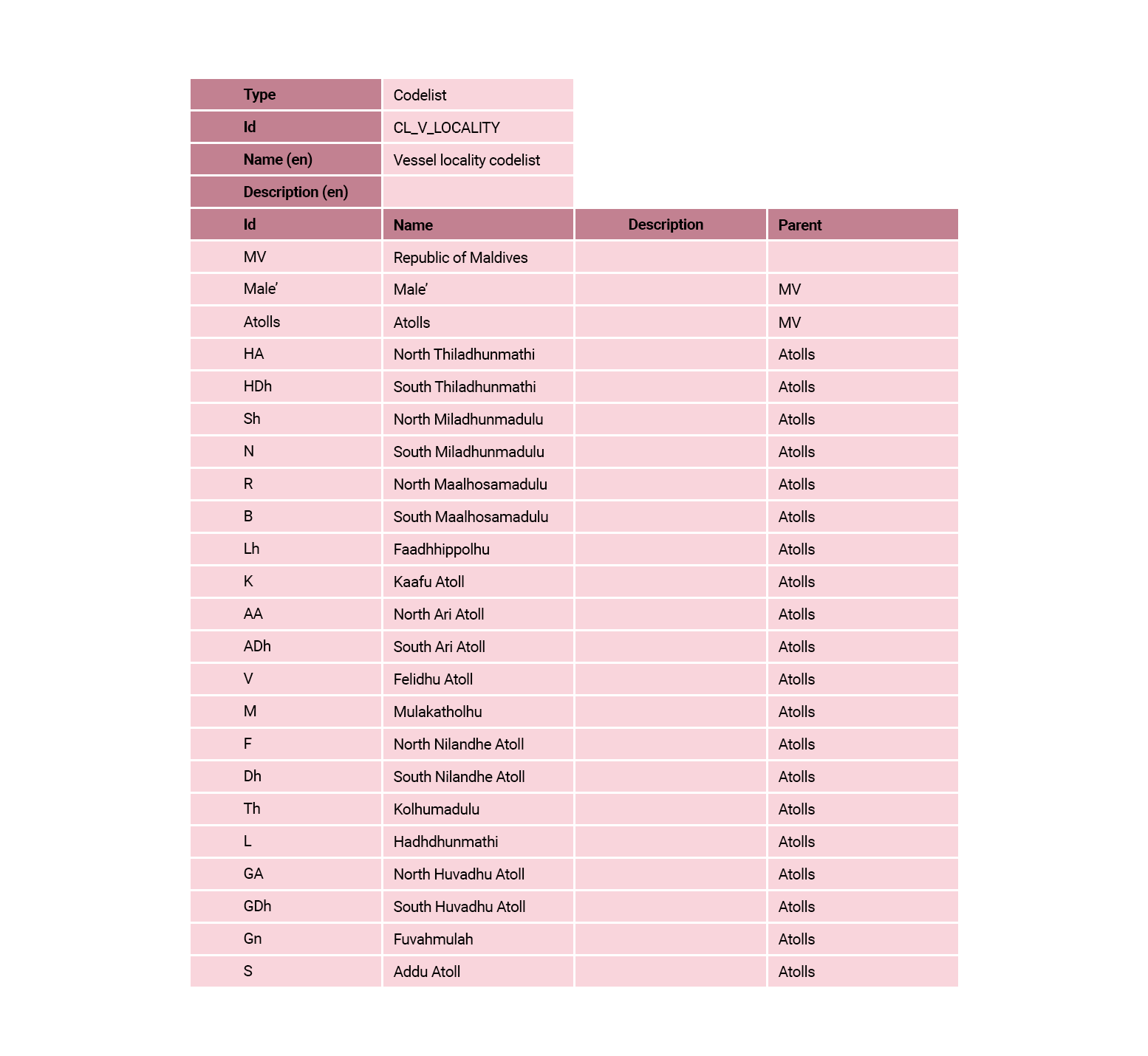
The CL_V_LOCALITY codelist has been implemented using a parent/child hierarchy approach. The way to read the table is by reviewing the Parent column on the right of the table and interpreting the information as follows:
- Id ‘MV’ has no parent and is therefore the highest branch in the tree.
- Id ‘MV’ is the parent of two children:
- Id ‘Male’
- Id ‘Atolls’
- Atolls is the parent of 20 children, the first one is Id ‘HA’ and the last one Id ‘S’.
Many tools will recognise this parent/child implementation and represent the structural metadata in data tables in accordance with this hierarchical structure.
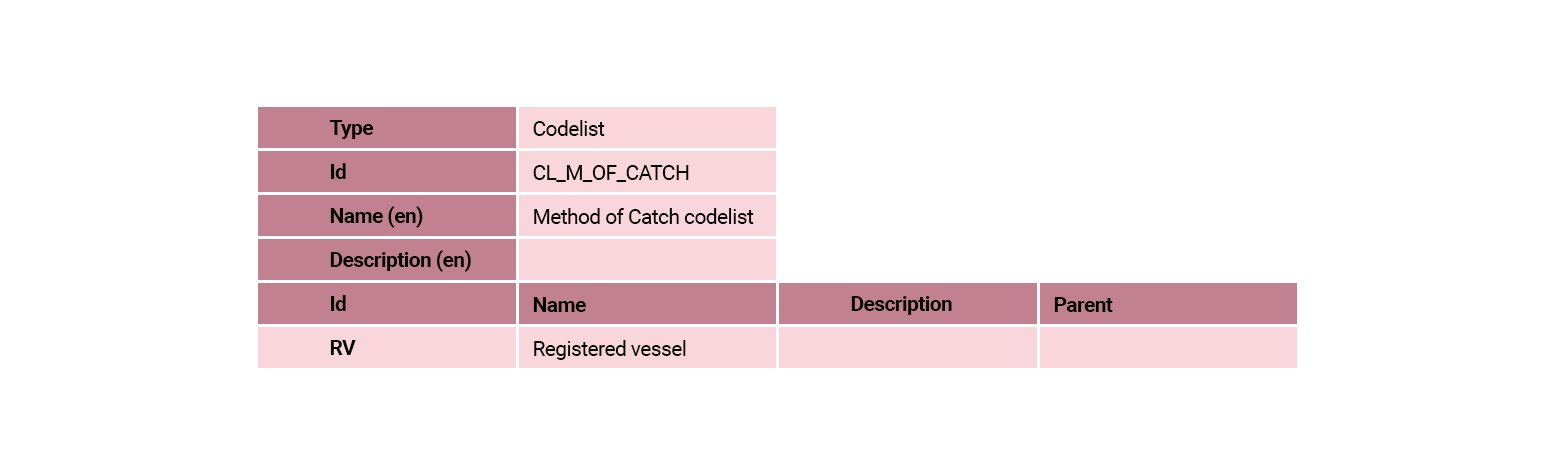
The CL_FREQ codelist is one of the cross-domain codelists that is maintained by the SDMX governance groups. There are references to the cross-domain codelists in the support materials provided at the end of this module.
What you learned

The aim of the Getting Started with SDMX module is to familiarise you with essential SDMX elements and to help bridge the gap between statistical structural modelling terminology and SDMX terminology.
In this Essential SDMX Structural Modelling module, the SDMX elements necessary for representing all of the concepts described in the Statistical Logical Model were defined and covered in detail.
The Statistical Logical Model was mapped to the SDMX Information Model to illustrate that while SDMX terminology may differ from statistical terminology, there is a straightforward mapping between the two sets of vocabulary.
With practice, your confidence in structural modelling will increase and modelling more complex examples will be possible. Additional course materials are planned to ensure that learning resources will be available to help you with the journey.
What do you know?
You have now completed Essential SDMX Structural Modelling, but before moving on to the module summary, try this final question.
You’ll recall that when mapping statistical concepts to the SDMX Information Model, we are primarily concerned with the SDMX artefacts which describe data. But determining whether a concept is a dimension, or an attribute is not always obvious. To differentiate between the two, you should ask the following question:
“If the concept is assigned different values, does the data take on a different meaning?”
Which of the following are the correct responses?
If the answer is ….
Select the TWO correct answers and then select Submit.
If the answer is:
- YES: the statistical concept should be identified as a dimension.
- NO: the statistical concept should be identified as an attribute.
If the answer is:
- YES: the statistical concept should be identified as a dimension.
- NO: the statistical concept should be identified as an attribute.
If the answer is:
- YES: the statistical concept should be identified as a dimension.
- NO: the statistical concept should be identified as an attribute.